大数据智能技术“3+3”学习路线

学习大数据智能技术不能像炒菜一样,等到把所有材料准备好了才下锅。这是因为大数据智能技术一是技术体系庞杂,二是应用目标广泛,三是实践性较强,就算学习多年也难说能全面掌握。建议初学者结合自己的兴趣或工作、项目需求,找一个点深钻进去,掌握这个点的相关技术和算法,深入理解其分析的流程、应用和评价等环节,搞透彻一个点之后,再以点带面,举一反三,逐步覆盖大数据分析各个领域,从而掌握完整的技术知识和应用经验,这是学习大数据智能学习的关键。
所以怎么从点到面,构建大数据智能领域完整的知识结构和分析能力体系至关重要,某些方面的技术和语言只是工具,样样都懂容易,深入了解一门很难,特别是如何抓住本质的东西。大数据智能的知识结构,既有精深的大数据基础理论和技术知识(比如概率、最优化、算法设计等内容),又需要有广博的知识面和应用全局观(比如业务分析、数据管理和系统架构设计等内容),掌握大数据智能技术产业发展所需要的最合理、最优化、最关键的技术和业务知识。通过合理的知识结构和科学的大数据思维方法,提高大数据智能应用分析的实战技能。
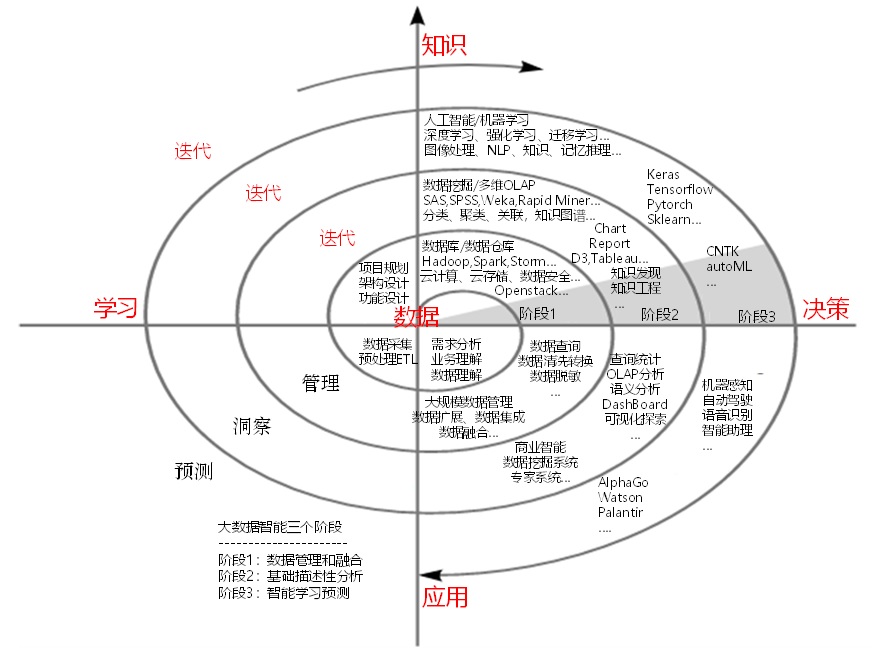
大数据智能是一个系统工程,涉及的关键技术和应用环节众多。在学习不同阶段的技术时应该各有侧重。上图从技术和业务角度,分析了大数据智能的应用周期和技术链,通过数据的学习,获取知识,基于知识和规律进行决策和应用,是一个闭环迭代的过程。从管理、洞察到预测对大数据智能应用整个技术体系的学习划分为如下三个阶段。
(1)数据的管理和融合阶段:这是大数据分析的基础,也是从IT向DT进化的第一步。这个阶段的重点是大数据基础设施的建设,核心目标是要把大数据存起来,管起来,用起来,同时要考虑大数据平台和原有业务系统的互通及联合问题。一句话,要做好全局数据集成,解决数据孤岛问题!要完成大数据基础设施系统(主要是采集和存储)的搭建和集成开发,就要明确数据采集、存储和分析各层核心组件的选型和使用,搭建稳定的大数据集群,或选择私有云方案的服务集群,与生产系统并线运行,使待分析的历史数据和实时数据得以采集预处理并源源不断流入大数据系统。
当然,在启动这一工作之前,需要明确整个大数据智能的应用目标,做好需求分析、数据理解和项目规划设计。其中涉及的关键技术包括软件工程、数据库、NoSQL、数据仓库、云计算和管理平台的开发等,这一阶段主要解决大数据的采集、存储和融合等基础管理层面问题。主流的开源大数据基础框架(如Hadoop、Spark、OpenStack等),其核心功能就是满足大数据的融合和管理。这个过程当然还涉及很多技术细节,如数据的采集、清洗和隐私脱敏等数据预处理工作,数据抽取、转换和和集成融合、数据安全管控等问题。
(2)基础描述性分析阶段:主要完成大数据基础分析工作,如传统的数据分析类系统、商业智能、数据挖掘、专家系统等。此阶段主要定位于离线或在线对历史数据进行全局条件下的基本描述统计分析,对大数据能进行海量存储条件下的交互式查询、汇总、统计和可视化。如果建设了BI系统,则还需整合传统BI技术进行OLAP、KPI、Report、Chart、Dashboard等分析和初步的描述型数据挖掘分析,并能快速验证描述分析结果进行调整,同时对大数据系统进行迭代升级开发。这个基础分析阶段是对数据集成、数据质量和基础模型有效性等的测试,也是对海量数据条件下的分布式存储管理和数据安全性保障的检验。需要掌握的技术涉及传统的数据挖掘、专家系统、多维OLAP分析和数据可视化等多个方面。
(3)智能学习预测阶段:大数据智能的高级预测分析和生产部署。在初步描述分析结果合理,符合预期分析目标,数据分布式管理和描述性挖掘模型稳定成熟的条件下,结合进一步智能处理业务点分析需求,采用如人工智能和深度学习、强化学习等适用海量数据处理的智能机器学习模型,进行高级预测性学习和分析。并通过逐步迭代优化机器模型和数据质量,形成稳定可靠和性能可扩展的智能处理模型,在相关业务服务中使用预测结果进行验证、支持和反馈,核心目标就是像Google大脑、百度大脑计划落地一样,建立企业未来的决策支持中心,并初步实现大数据智能!
这一阶段是大数据智能应用的最终目标,也是落地的关键点和难点,需要理解整个大数据智能的预测原理和数据意义,做好深度模型的设计调试、数据理解和迭代优化,至少能完成初步的机器感知和理解任务。其中涉及的关键技术包括人工智能、机器学习、深度学习、强化学习和自然语言理解、图像识别、知识图谱、语义分析等。主流的开源机器学习框架如TensorFlow、Keras、Pytorch、Caffe、Sklearn等,其核心功能就是满足大数据智能预测和学习建模。另外,行业的顶级AI系统如AlphaGo、Watson等都属于这一层级。在这个阶段的应用可以说涉及很多DT前沿信息技术,除深度学习、强化学习外,还有知识图谱、语义网络、自然语言理解、知识记忆推理等多个方面的内容。
在上述几个阶段的技术学习过程中,需要注意以下几个关键问题。
一是重视可视化和业务决策,大数据智能分析结果是为决策服务的,而大数据决策的表现形式——可视化技术的优劣起决定性作用,如前文介绍的Palantir。
二是问问自己,Hadoop、Spark等是必须要学的吗?这要从整个大数据技术栈来考虑技术的选择和技术路线的确定;Hadoop和Spark重在大数据的基础管理、存储和计算,不是智能学习系统的必要条件。
三是建模问题处于核心地位,模型的选择和评估至关重要,在课堂和实验室中,多数模型的评估是静态的,很少会考虑其运行速度、实时性及增量处理。而Kaggle竞赛中的各种Boost方法,XGBDT等模型,在数据挖掘和机器学习教材中却少有提及,所以要充分参考业界的实战经验,不能尽信书中所言。
四是开发语言的选择,基础大数据管理框架类系统Java是必须掌握的,应用级的机器学习和数据分析库Python是必须掌握的,而要深入各种框架和学习库的底层,C++是必须掌握的。
五是模型的产品化,将实际数据通过管道设计转换为输入特征传递给模型,如何最小化模型在线上和线下的表现差距,这些都是要应用研究落地的关键问题。
学习的三种方式:应用导向是关键
前面从技术应用的时间线的角度将大数据智能关键技术体系分了三个层次:一是数据的管理与融合技术,二是基础描述性分析技术,三是智能学习预测技术。这三个层面的技术各有侧重,有些还有交叉重叠。在学习过程中,很难做到面面俱到,全部掌握。那么要遵循一个什么样的学习路线才能事半功倍呢?不外乎如下三种套路,供读者参考。
一是像一些学校教学或培训机构的课程大纲一样:第一章是 Hadoop入门,了解什么是Hadoop,第二章介绍文件系统HDFS,第三章介绍Mapreduce,以及YARN、Mahout、Storm、Spark、机器学习、深度学习等,恨不得把所有大数据智能方方面面的技术都写上。我们要避免这样的学习方式,毕竟我们不能指望靠突击,在一夜之间就成为出色的数据科学家,即使是学生,在有限的时间条件下也只能系统地掌握几门课程。
二是从核心技术的角度进行突破,从数据科学、机器学习、大数据管理、认知计算、深度模型、Hadoop、TensorFlow、PyTorch等中,选择一个点深挖,快速成为一个细分领域的技术专家,比如要研究深度学习,那就从无到有,基于最基础的Python计算库如NumPy实现一个深度神经网络,而不是一上来就用TensorFlow甚至Keras,只用几行代码就可以搭建一个深度网络。这也是少数极客型技术高手最喜欢的套路。但这对基础编程和算法分析、系统架构等方面的能力要求极高,没有多年的设计研发经验很难快速上手。
三是从快速应用角度入手,以问题为导向、以应用为导向,快速设计原型系统,在宏观上搞清楚一个具体的细分领域,从问题分析、系统架构、编程设计实现等方面迭代完成一个小的项目,再对核心技术环节的原理、思想及设计编码实现方法等做系统的研究。这跟笔者在前文提出的敏捷大数据方法论一样:“大”数据“小”应用,面对庞大的智能技术体系,最好从一个小的切入点着手,而且这个点不是以技术为导向,而是以问题为导向。
为什么要这样?上述第一种方式不可取,敷“万金油”样样都学但很难深入,谈不上精通,而且很多情况是时间有限、条件不允许。第二种方式稍微好一些,但问题是技术包罗万象,要系统地掌握一门技术必定要花很多时间,那从哪个细分技术领域开始呢?这对没有经验的人来讲,面临机会和时间成本的挑战,一门深入的技术框架说不定还没完全掌握就快过时了(比如较早的深度学习框架Theano),而即使花大精力掌握的技术,却少有用武之地,这都是很有可能的。
综上所述,为什么大数据智能技术的学习要以应用为导向,因为技术只是工具,解决问题才是关键,大数据分析被誉为科学的“第四范式”,其核心就是要解决问题。搞清楚问题之后,技术的选择、技术路线的确定和技术学习才能有的放矢,所谓纲举目张,就是这个意思。
版权声明:本站原创和会员推荐转载文章,仅供学习交流使用,不会用于任何商业用途,转载本站文章请注明来源、原文链接和作者,否则产生的任何版权纠纷与本站无关,如果有文章侵犯到原作者的权益,请您与我们联系删除或者进行授权,联系邮箱:service@datagold.com.cn。

