中国人工智能系列白皮书-大模型技术(2023版)
大模型技术的发展历程
2006年Geoffrey Hinton提出通过逐层无监督预训练的方式来缓解由于梯度消失而导致的深层网络难以训练的问题[1],为神经网络的有效学习提供了重要的优化途径。此后,深度学习在计算机视觉[2]、语音[3]、自然语言处理[4]等众多领域取得了突破性的研究进展,开启了新一轮深度学习的发展浪潮。总结过去十多年的技术发展,基于深度学习的人工智能技术主要经历了如下的研究范式转变:从早期的“标注数据监督学习”的任务特定模型,到”无标注数据预训练+标注数据微调”的预训练模型,再到如今的”大规模无标注数据预训练+指令微调+人类对齐”的大模型,经历了从小数据到大数据,从小模型到大模型,从专用到通用的发展历程,人工智能技术正逐步进入大模型时代。
2022年底,由OpenAI发布的语言大模型ChatGPT引发了社会的广泛关注。在“大模型+大数据+大算力”的加持下,ChatGPT能够通过自然语言交互完成多种任务,具备了多场景、多用途、跨学科的任务处理能力。以ChatGPT为代表的大模型技术可以在经济、法律、社会等众多领域发挥重要作用。大模型被认为很可能像PC时代的操作系统一样,成为未来人工智能领域的关键基础设施,引发了大模型的发展热潮。
本次大模型热潮主要由语言大模型(亦称为大语言模型)引领。语言大模型通过在海量无标注数据上进行大规模预训练,能够学习到大量的语言知识与世界知识,并且通过指令微调、人类对齐等关键技术拥有面向多任务的通用求解能力。在原理上,语言大模型旨在构建面向文本序列的概率生成模型,其发展过程主要经历了四个主要阶段:
1)统计语言模型:统计语言模型主要基于马尔可夫假设建模文
本序列的生成概率。特别地,N-gram语言模型[6]认为下一个词汇的生成概率只依赖于前面出现的N个词汇(即N阶马尔可夫假设)。此类语言模型的问题在于容易受到数据稀疏问题的影响,需要使用平滑策略改进概率分布的估计,对于文本序列的建模能力较弱。
2)神经语言模型:针对统计语言模型存在的问题,神经语言模型主要通过神经网络(MLP[7]、RNN[8])建模目标词汇与上下文词汇的语义共现关系,能够有效捕获复杂的语义依赖关系,更为精准建模词汇的生成概率。进一步,word2vec[4]简化了神经语言模型的网络架构,可以从无监督语料中学习可迁移的词表示(又称为词向量或词嵌入),为后续预训练语言模型的研究奠定了基础。
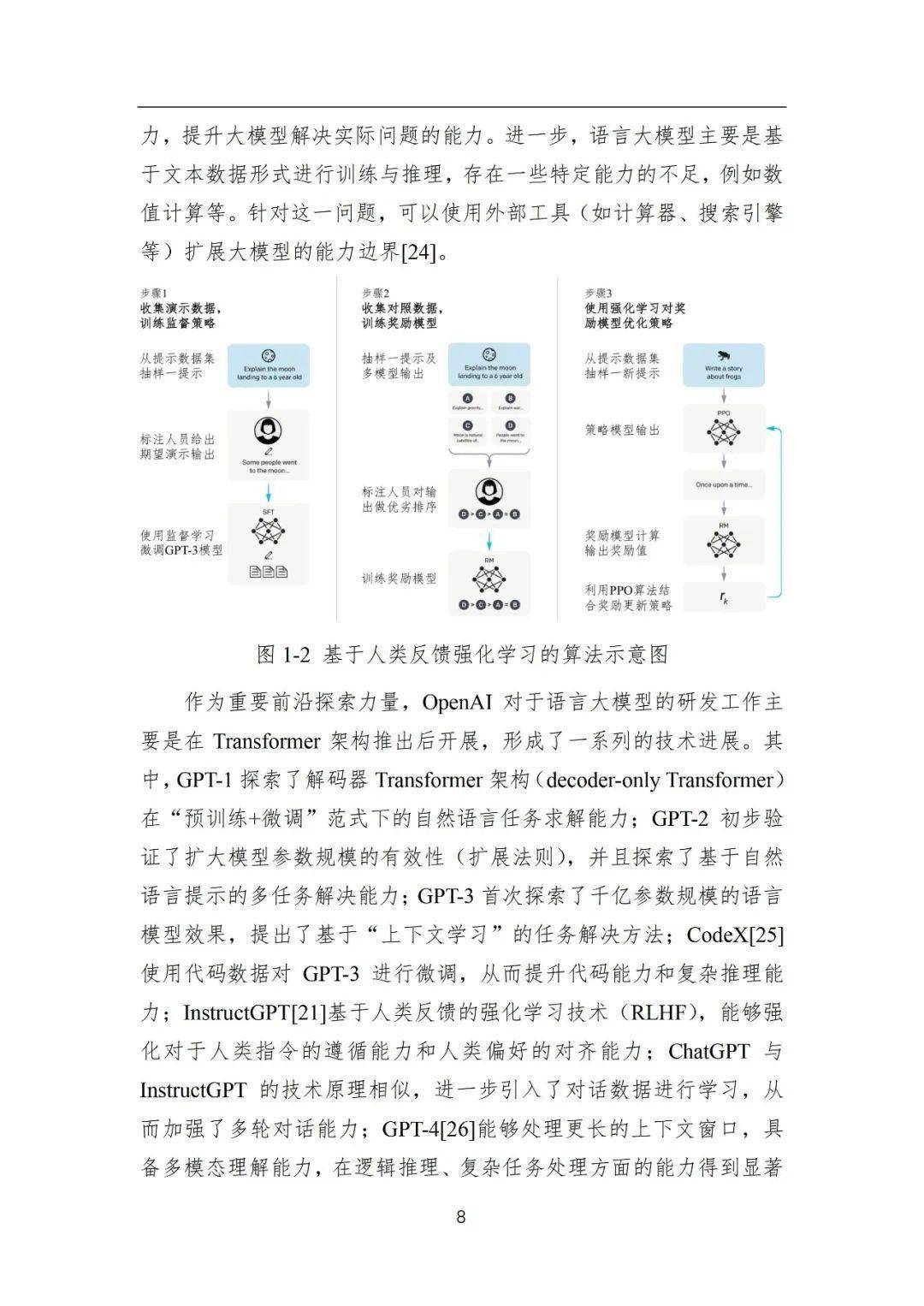
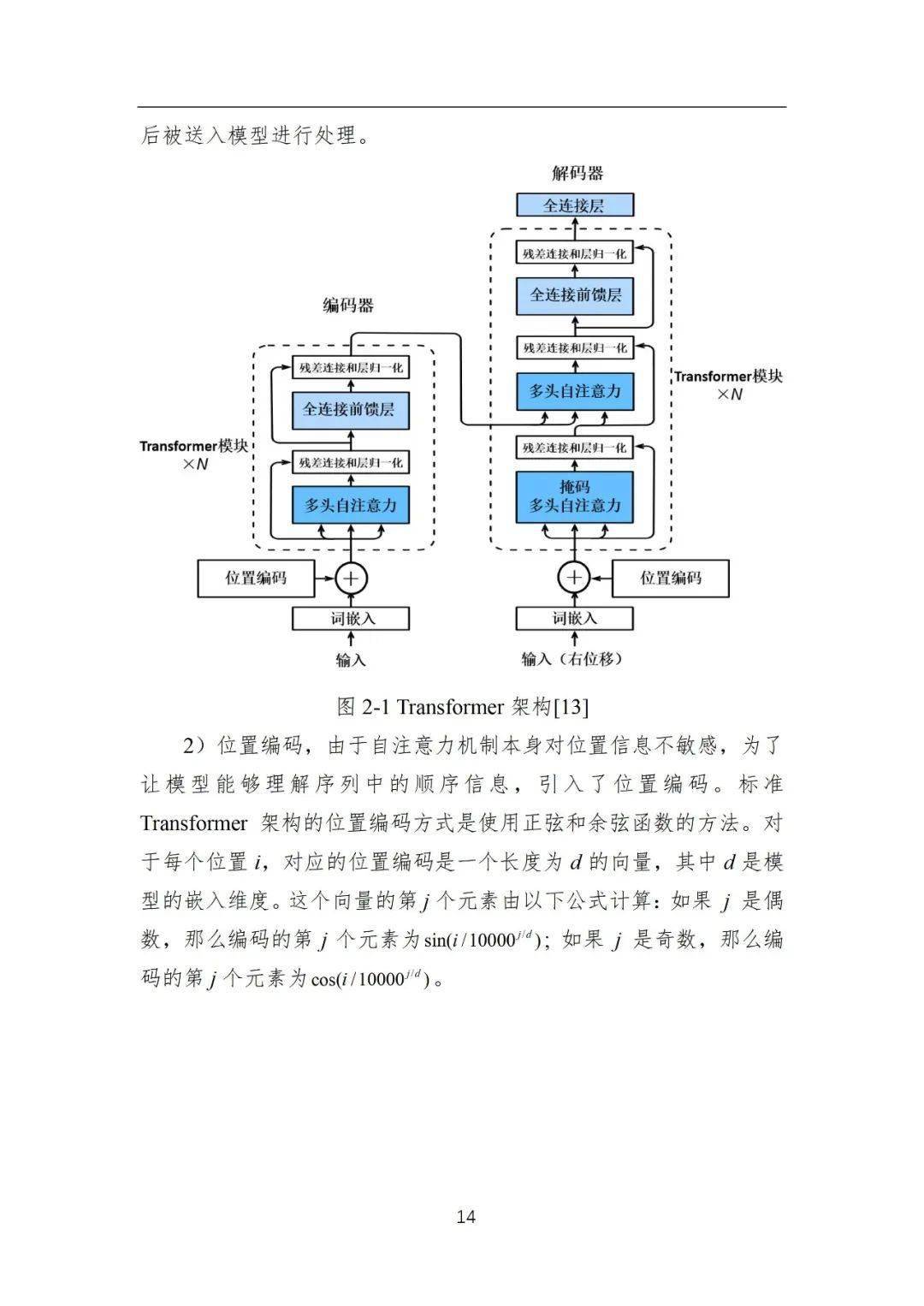
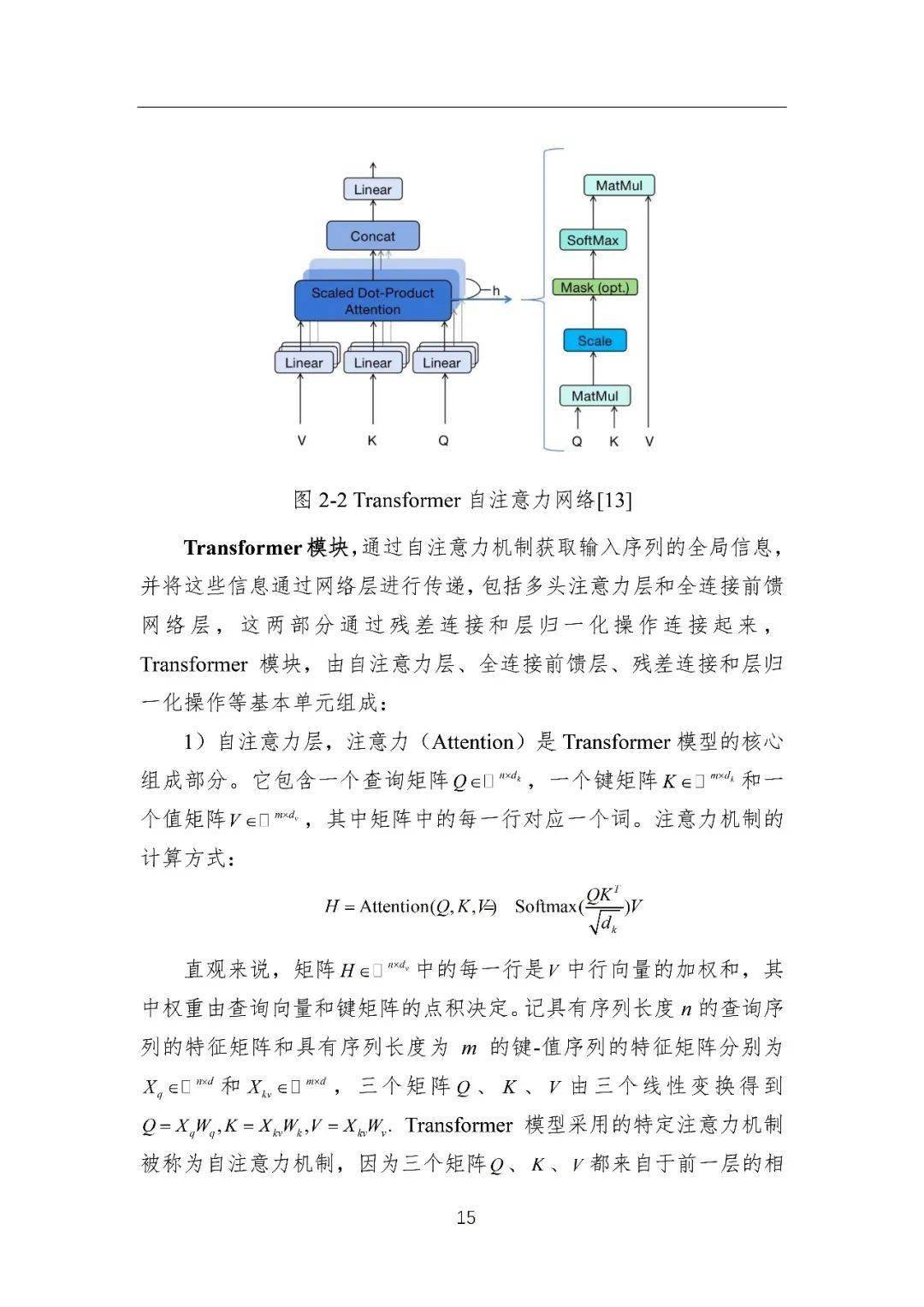
3)预训练语言模型:预训练语言模型主要是基于“预训练+微调”的学习范式构建,首先通过自监督学习任务从无标注文本中学习可迁移的模型参数,进而通过有监督微调适配下游任务。早期的代表性预训练语言模型包括ELMo[9]、GPT-1[10]和BERT[11]等。其中,ELMo模型基于传统的循环神经网络(LSTM)[12]构建,存在长距离序列建模能力弱的问题;随着Transformer[13]的提出,神经网络序列建模能力得到了显著的提升,GPT-1和BERT都是基于Transformer架构构建的,可通过微调学习解决大部分的自然语言处理任务。
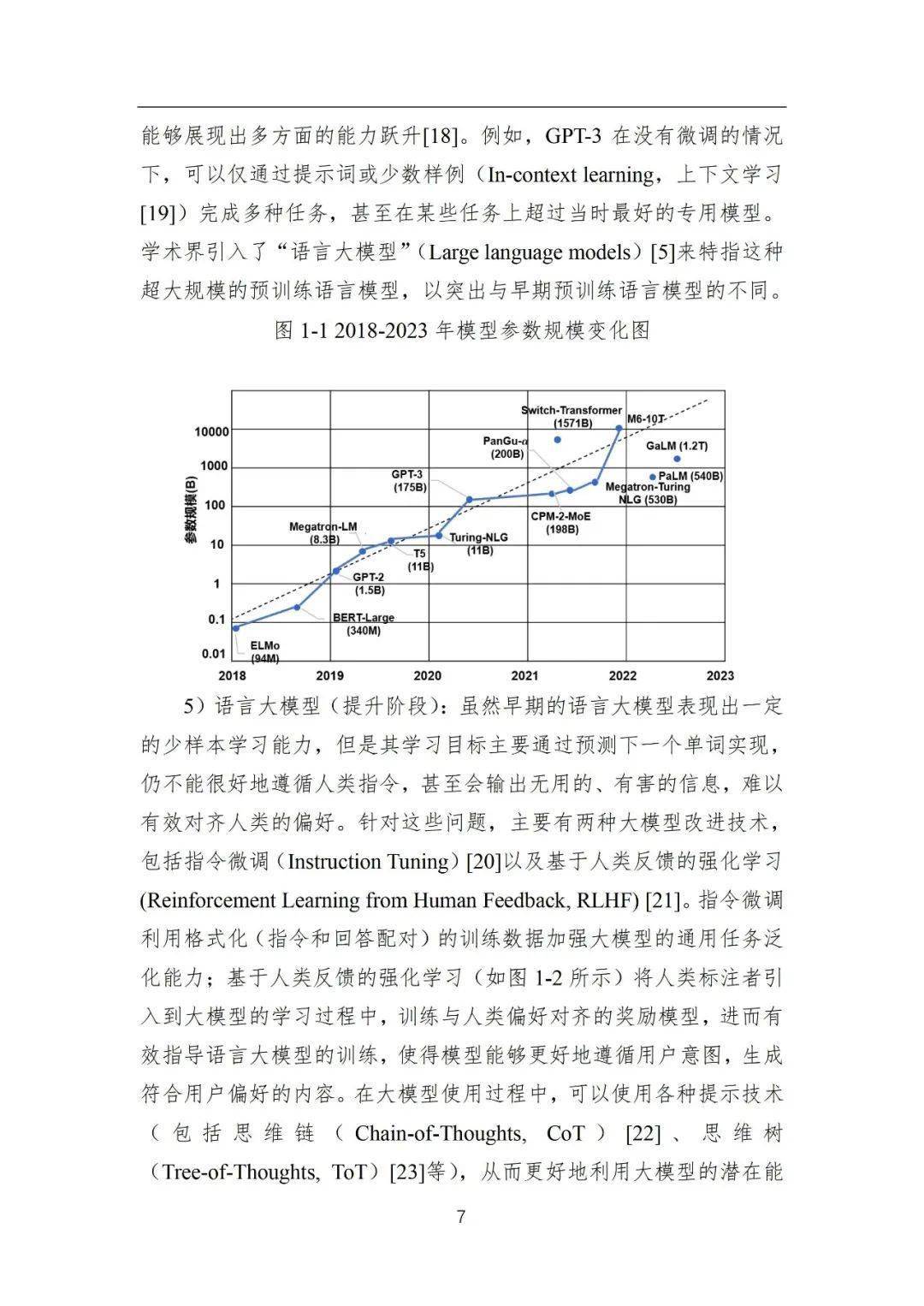
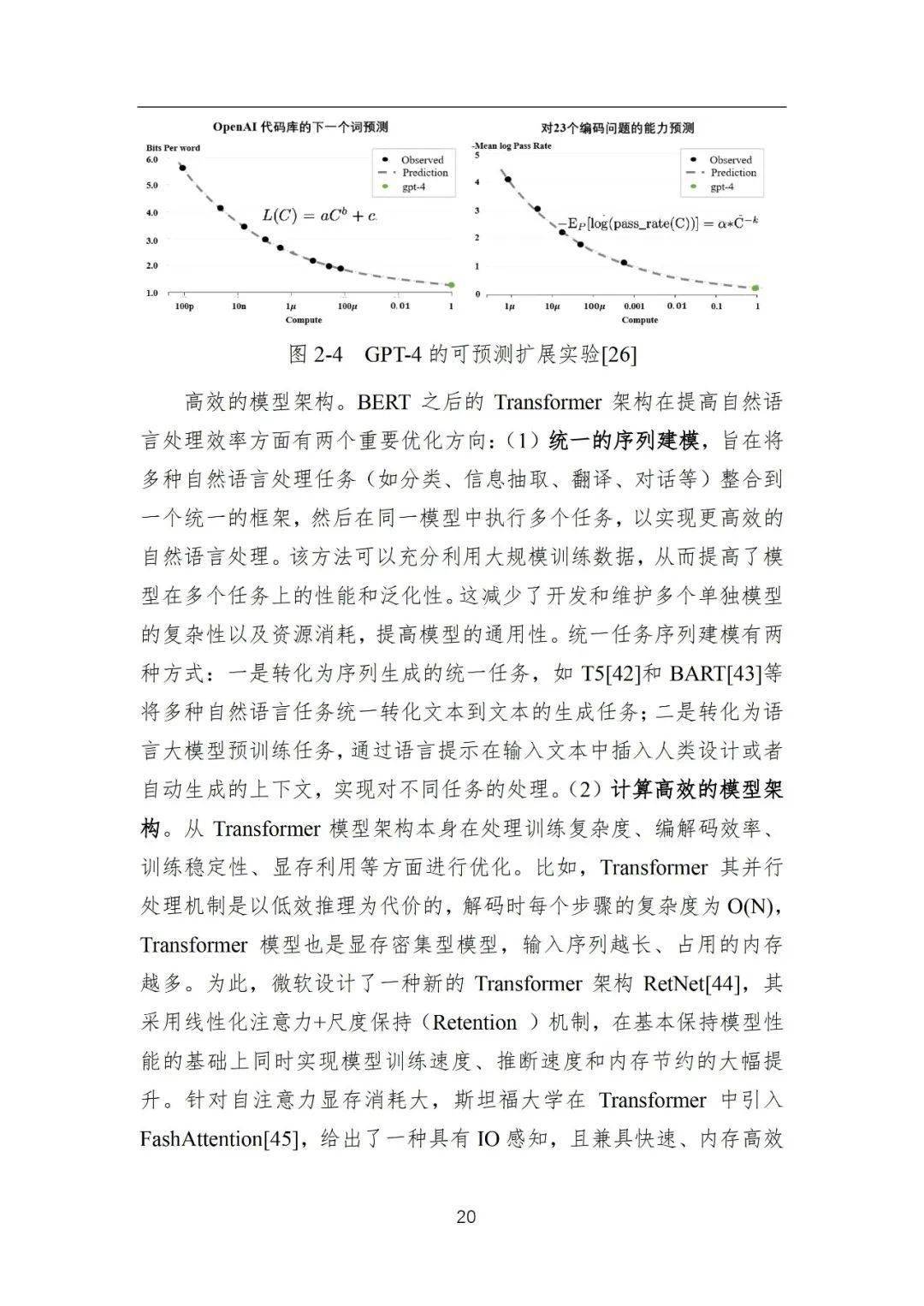
4)语言大模型(探索阶段):在预训练语言模型的研发过程中,一个重要的经验性法则是扩展定律(Scaling Law)[14]:随着模型参数规模和预训练数据规模的不断增加,模型能力与任务效果将会随之改善。



















来源:https://www.sohu.com/a/728552419_468661
版权声明:本站原创和会员推荐转载文章,仅供学习交流使用,不会用于任何商业用途,转载本站文章请注明来源、原文链接和作者,否则产生的任何版权纠纷与本站无关,如果有文章侵犯到原作者的权益,请您与我们联系删除或者进行授权,联系邮箱:service@datagold.com.cn。

